 Explaining the predictions of the CodeBERT model for semantic code clone detection
Explaining the predictions of the CodeBERT model for semantic code clone detection
Abstract
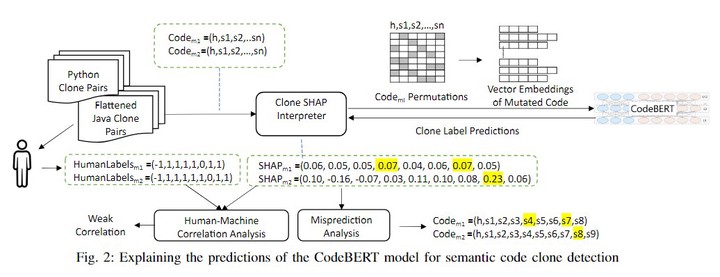
Accurate detection of semantic code clones has many applications in software engineering but is challenging because of lexical, syntactic, or structural dissimilarities in code. CodeBERT, a popular deep neural network based pre-trained code model, can detect code clones with a high accuracy. However, its performance on unseen data is reported to be lower. A challenge is to interpret CodeBERT’s clone detection behavior and isolate the causes of mispredictions. In this paper, we evaluate CodeBERT and interpret its clone detection behavior on the SemanticCloneBench dataset focusing on Java and Python clone pairs. We introduce the use of a black-box model interpretation technique, SHAP, to identify the core features of code that CodeBERT pays attention to for clone prediction. We first perform a manual similarity analysis over a sample of clone pairs to revise clone labels and to assign labels to statements indicating their contribution to core functionality. We then evaluate the correlation between the human and model’s interpretation of core features of code as a measure of CodeBERT’s trustworthiness. We observe only a weak correlation. Finally, we present examples on how to identify causes of mispredictions for CodeBERT. Our technique can help researchers to assess and fine-tune their models’ performance.