 Methodology for comparing human intuition with model intuition for semantic code clone detection
Methodology for comparing human intuition with model intuition for semantic code clone detection
Abstract
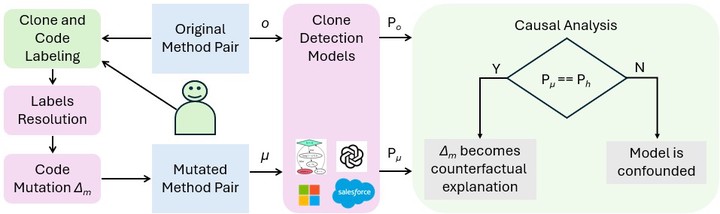
Deep Neural Network-based models have demonstrated high accuracy for semantic code clone detection. However, the lack of generalization poses a threat to the trustworthiness and reliability of these models. Furthermore, the black-box nature of these models makes interpreting the model’s decisions very challenging. Currently, there is only a limited understanding of the semantic code clone detection behavior of existing models. There is a lack of transparency in understanding how a model identifies semantic code clones and the exact code components influencing its prediction. In this paper, we introduce the use of a causal interpretation framework based on the Neyman-Rubin causal model to gain insight into the decision-making of four state-of-the-art clone detection models. Using the causal interpretation framework, we derive causal explanations of models’ decisions by performing interventions guided by expert-labeled data. We measure the alignment of models’ decision-making with expert intuition by evaluating the causal effects of code similarities and differences on the clone predictions of the models. Additionally, we evaluate the similarity intuition alignment, robustness to confounding influences, and prediction consistency of the models. Finally, we rank the models in order of most aligned and thus most reliable to least aligned and thus least reliable for semantic code clone detection. Our contributions lay a foundation for building and evaluating trustworthy semantic code clone detection systems.